
Perceptive Content / ImageNow iScript Part 2
Back by popular demand, RPI Consultants offers this second installation of Office Hours for Perceptive Content / ImageNow iScript. During this recording, you will find live demonstrations and hear interactive Q&A related to iScript, Perceptive Content’s custom automation engine.
Transcript
Speaker 1:
Hello, welcome to Office Hours, everyone. This is RPI’s Monthly Office Hours where we just try to show you cool stuff and try to give you an opportunity to ask us questions about what we’re presenting or if you have questions that are unrelated, feel free to ask those as well. We’re just trying to keep an open dialogue with everybody to be an open resource. Before we get started with my presentation, one thing I want to point out is in the webinar Menu, there should be a drop-down option for handouts, the Handouts Section. There’s a Word document that’s included with this webinar. It’s called RPI iScript Resources.
That document is the same document that we use in part one of this series, but it’s still relevant to what we’re talking about today. If you missed the first part of this, please open that up. I’m actually going to share and go through a couple things here, but definitely hold on to this because it’s a great resource to just walk you through the different things that you can use on your end to help yourself with iScript. Last time we did this, we spent a little bit of time going through the basics of iScript and some of the basic things that you can do with it. This time, what we’re going to do is focus more on database queries.
We’re going to look at how do we connect to a database, how do we run a query. I specifically have a reindex iScript that I’m using. It’s like an example of HR script. I have an employee ID that I’m going to query against a database table to find employee information and index the document. We’ll be indexing index keys like field one through five and custom properties so that we can show you those differences. In the last, if you missed the first part of this, I definitely recommend going back and taking a look at that. I’m not going to cover all of the little basics like I did last time. It’s really helpful if you go back on that one. It was a little bit longer because we tried to cover a lot of stuff at iScript. Definitely go back and look at that because it was a lot of information.
Let me show you what I’m talking about here. This is the important links and resources for iScript document that’s in the Handout Section. The main things we’re going to be talking about today and really that you talk about all the time when we’re discussing iScript are the STL Files and we’ll be talking about the INDocument object. The STL Files, if you aren’t familiar with them, is just the standard template library of functions that are available for you to use within iScript. They’re generally included with your system. If you just go to your Scripts Directory, you’ll see the STL File in there. If you don’t have them, you can grab them off of Hyland’s website.
The really nice thing about that group of STL Files is the index. Inside of the STL Folder, you’ll find an index HTML and it takes you to this page. Let me get this thing out of here. Minimize this. There we go. On the STL Index page, we just have kind of a group on the left side, groupings of functionality. For example, if I break out document, it’s going to show me a whole bunch of different functions that are available to me that are specific to documents within Perceptive Content. For example, if I want to reindex a document like what we’re going to do today, I can find that Reindex Document function here, click on it and it’s going to show me not only example code but also like what it returns, what I need to pass into it.
Here’s an example of the method where I can break this out, I know that my function is Reindex Document, and it shows me the different items that I need to pass in into that function group to run properly. It also outlines like our optional items. You’ll see specifically optional called out in here for certain items in that function. This is definitely super handy. You can save tons and tons of time if you utilize STL instead of trying to just go willy-nilly inside of the iScript. It really speeds everything up because anything, pretty much anything that is done a lot in an iScript, they’ve covered in the STL. Creating documents, routing documents, even archiving or even things not related to documents like date conversions.
If I want to break out the date section, I have my Convert to Date String. If I have a data type, but I require a string data type in what I’m passing it to, I can use this function to convert that data type to a string to pass that over which is another example of something that we’ll do today. I don’t want to go too deep into this. If you want any more information about this, again go back to the part one video that we should be hosting on the RPI website and it will cover in depth a lot of this other stuff. Let me just jump straight into what we have built. I have a test environment, our internal test environment for ImageNow and also my test SQL Server.
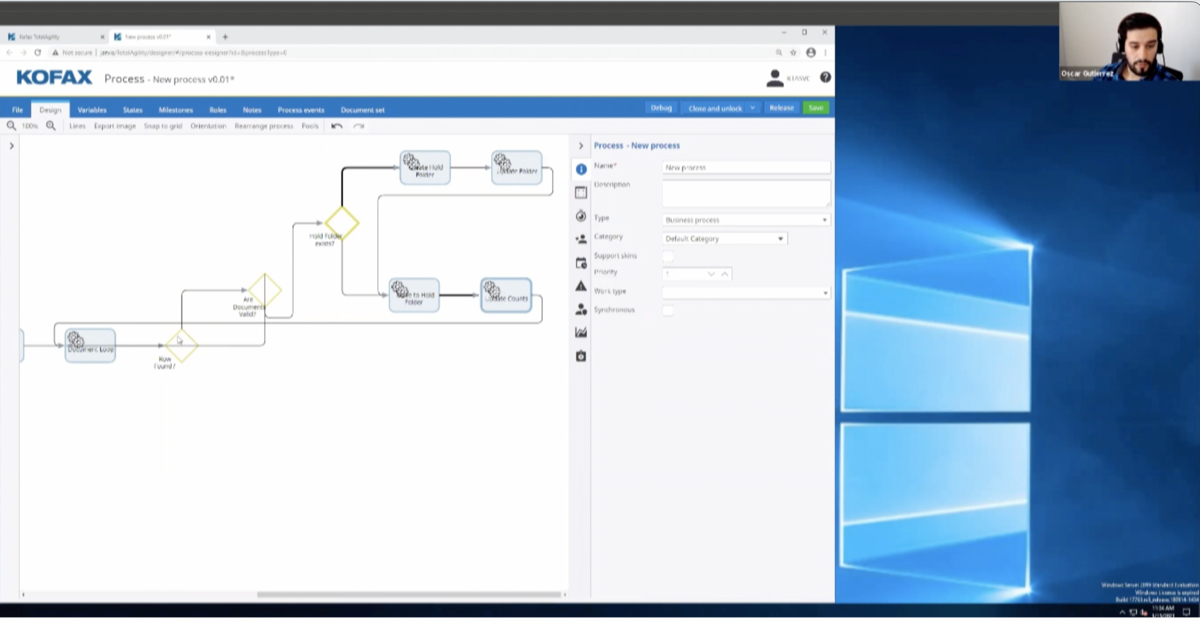
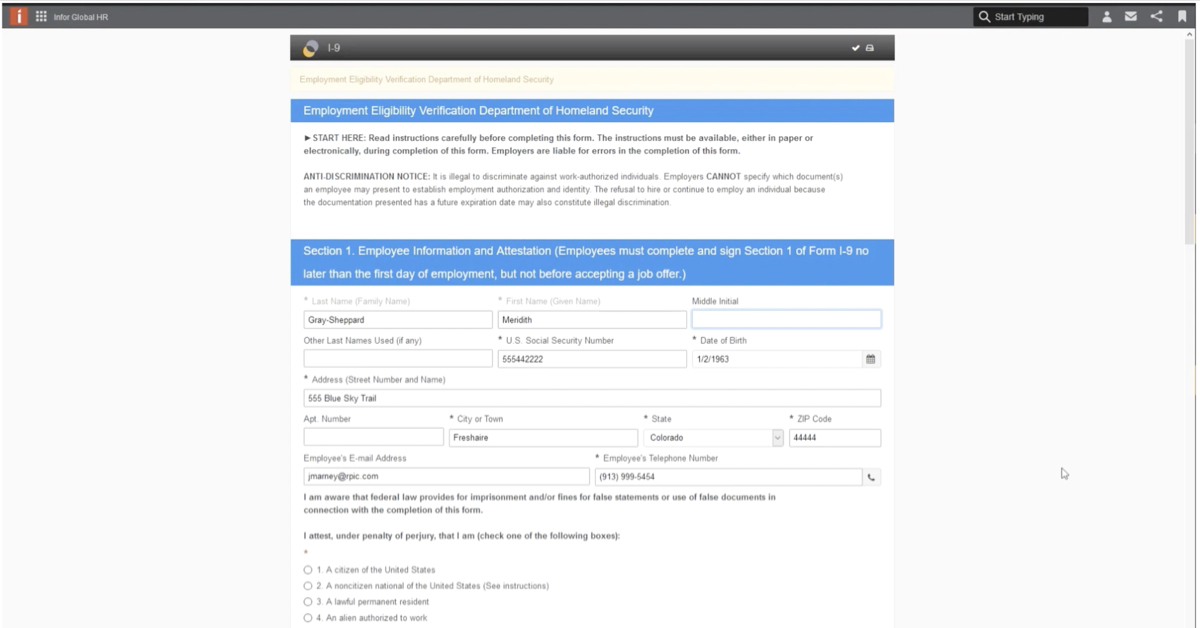
I’m going to show you the table that I built that we’re going to be querying against and the script that I put together and how I put it together inside of workflow. First, let’s take just a look at this table. This is a really tiny table. There isn’t a whole lot of data in it. I just put it directly in the INow database. Really, all we have here is an employee ID column and then some employee information like first name, last name, middle name, date of birth, their start date or hire date, their position number and their supervisor. These are going to be the data elements that we want to capture inside of our iScript. To give you kind of a scenario for what we’re trying to build here, let’s say that you had HR documents that you were wanting to read into the system, and at time of import, maybe all you had was the employee ID.
What we’re doing is we’re recreating that with our Doc Import Queue here. I have some documents currently sitting in this workflow queue that don’t have any data in it other than the employee ID. This is a really simple workflow where all I’m doing is just moving them to my Doc Indexing Queue that kicks off my iScript, my Indexing Script, and then it will either move it to complete or to the error queue depending on whether or not it’s successful.
This is my Document Import Queue. You see that I’ve got documents here. All of these documents that I’ve got inside of here are pretty much blank, except for my employee ID. See that I also have a couple custom properties here. To compare what I have in my document and my database, I have my full name. Full name in this scenario, what I’m going to do is I’m going to take last name, comma, first name, space, middle initial. This is going to require us to pull back all three, all of the data for first name, last name and middle name and then do some massaging for that data that’s returned to place it into our field one full name field.
Field two his date of birth. That’s going to match up to my date of birth column. Position number, I have this field three. Again, position number in the column there. I will be setting unique ID. This will be an example of an STL function that we can use that maybe isn’t related to the database, maybe we didn’t have a unique ID when I pulled in for some reason. We want to go ahead and add it now. The custom properties for start date and supervisor again, just more columns inside of the database here. Let’s take a look at the iScript. To start this iScript-
There we go. Is that better? To start with the iScript, I started just using my template workflow. In the first video, I showed people that I had a template workflow and a template in tool iScript shell. This is kind of just a jumping off point. It’s easier for me to just start from something like this, so I don’t have to type it all out again, but basically all this is there’s not really any functionality in here. I’m just starting my process for me, so I don’t have to retype everything out every time. If you have these and you were part of the part one video, then great. If not, I will have my Mike Hopkins send out a copy of those templates after this presentation is over because they’re pretty handy.
Again, if you missed part one, the difference between workflow and in tool that I’m talking about is essentially just, “Are we tying into a workflow queue as a workflow action or are we using it as like a scheduled task running from a batch file?” or something like that. In this scenario, we’ll be doing everything through workflow. I started with this workflow template and then just add it on to it. This is the actual iScript. Generally, what I like to do inside of these iScripts and what you should always see in the iScript is a summary of the script process. To go through that, it’s essentially all it’s doing is input. When the document enters the indexing queue, it kicks off the iScript. The iScript will check the employee ID and then run query based on that employee ID against my employees table.
The data that’s returned, returns in an object where I will take the data from each of the columns, apply it to the document and then route it forward to the indexing complete queue. If there’s an error, like if there’s no query return or if the database can’t connect for some reason or anything like that, then I’m routing into my error queue. We’ll walk through all of that step by step.
Once we get past the comment section up here, that’s just giving some basic information about the script, the next area is the STL Packages. This is just where I’m linking in the STL functions that I’m using within the STL Directory. Since we’re here already, I may as well just go ahead and show you. So, where I’m talking about the STL Files, if you go to your Scripts Directory inside of in-server, you’ll find an STL Folder right here. This is going to be where I can find my packages my documentation and everything that I can use. I go more in depth on that in the first video if you need more information.
The STL functions that I’ll be using inside of this iScript are iScript Debug which is something that you’ll pretty much always have an iScript because it’s how you log out information into the script to log. I’ll use the route item function to route documents from queue to queue. DBAccess I use to not only open the database, but to also perform the query. Reindex Document is what reindexes the fields or the index keys on the ImageNow documents, so field one through five drawer document type. Property Manager is what is used for custom properties. I can’t just run the Reindex Document function and update all of the index keys in the custom properties because they’re really separate data types. I’ll use Property Manager separately after reindexing the document to cover the custom properties.
I use Convert to Date String to convert a data type to a string data type or one of those. I’ll get into that a little bit more later on when we’re actually in the code. Then I’m using Generate Unique ID to generate one of those Perceptive Content unique IDs that you’re probably familiar with into field five. One other thing to mention too, you won’t always see this link SEDBC line here, but I have to link this in specifically for my DBAccess script. The STL DBAccess JS requires us to link this in for it to function. Let’s say you were doing this from scratch, and you forgot to add in the SEDBC, it will actually log out for you that it needs that included. It’s pretty obvious that you need to add that.
Next is the Configuration Section. This again is a standard section in an iScript where we can determine whether or not we want to do dry runs, if we want to log to file our console, split logging by thread our debug levels, which we went into in depth in the first video and the max log file size. Most of this is pretty standard, so I generally just use whatever is already in the template. Then if I need to adjust anything, I’ll adjust from there, but most of the time to stay there. The only other thing that I might adjust on the fly is the debug level after it’s done. After we know everything works and we move this to prod, we don’t really need it set to the highest debug level anymore. I’ll just flip that over to zero or one.
Next is the Global Variable Section. This is where we start moving from generic to script specific. Inside of this section, this is really the section where I’m trying to tell users, “It’s okay for you to come in here and adjust this if you need to adjust it for something reason.” Let’s say that there is a workflow change made and we had to change the error queue name or something like that. They could come in here and change the queue name to whatever it needs to be. Inside of my Global Variables, I have my error queue, my complete queue defines for routing.
I’m specifying which index key holds my employee ID. That way, if they decide that they want to store the employee ID in a different field in the future, we can change that. There is a huge code change. I also have my database login information set here. The way that we’re going to be connecting through the database is through an ODBC connection. I have my Perceptive Content ODBC connection set up here. This is just the same one that I’m using for ImageNow because I’m hinging this table just off of the INow database. All I’m telling it is to use that DSN with this username and this password to get into the database.
I have my query. This is actually going to be the query that I’m running to find my information. All of my columns match up to the column names that are inside of the table. Again, I’m pulling first name, last name, middle name, date of birth, start date, position number and supervisor from the employees table where employee ID equals, and I have kind of a funny looking employee ID string here and the only reason that I do this is because I am intending on replacing this later on in the script. I’m adding those front and back carrots just to make it easy to make it like a unique string that’s easy for me to find and replace later on. This will be replaced with whatever value is currently stored in field four.
I have this section commented out for now. This is a little bit of advanced steps that I’ll show you later on after we’ve gone through the basic version. My execution method is workflow again because it’s an inbound action inside of the workflow queue. I’m starting up my debug variable just so that I can use it for my debugging once the actual main script body starts, which is what we get into now. In my main script body, this is where I’m just starting logging. This up to this point here, line 105, is pretty much what I have built out in the workflow template. We’re pretty much always going to start our debugging. If it’s a workflow script, I’m always going to have my workflow item.
The workflow item in this case is just the item that has entered the workflow queue. Then using that workflow item, I can use that to get the actual Perceptive Content document. Whenever you’re thinking of a workflow item inside of Perceptive Content, it’s not the true Perceptive Content document. I couldn’t get all of the document data from just the workflow item, it’s almost more like a shortcut to the document itself. When I’m reading in the workflow item here, this isn’t going to give me everything that I need for processing, I still need to get the actual INDocument object for the document.
Then, just to pause really quick now that we’re talking about INDocument, I want to go back to that handout. The INDocument is what I’m talking about right here. In this document, I’ve embedded the link in here. I’m going to open up the hyperlink for INDocument. It’s going to take us over to docs.hyland.com or should. Let’s see if my … There we go. This is really, really handy because the INDocument, it’s rare that you’ll be working with an iScript that doesn’t use the INDocument in some way. The INDocument object contains basically every little bit of information about a document inside of ImageNow. All of the index keys, the creation time, creation user, anything that you’re looking for that’s tied to a document you can generally find in the INDocument object.
This link that I provided inside of that handout really will go through all of the different keys tied into that tied into that object. You can kind of search around in here to find specifically like right here. It’s talking about doc.id, will pull back the document ID. doc.drawer pulls back the drawer name. These are all just keys inside of the greater INDocument object. If I set for example, my doc here to a new INDocument using the workflow item object ID, this is what is returned. Doc is now an object where I have keys like field one that store my field one value. If I typed out doc.field1. If I said var value = doc.field1, whatever I currently have in field one of that document will now be what value is equal to. It’s really easy to pull information back from a document using the INDocument object.
Getting the info is the next step. This is basically just running a function that then pulls in that data. Really, I should have done the doc.field1 after getInfo because getInfo is what’s populating our keys with actual values. Assuming that I don’t run into any errors, you can see I’m using my exclamation point false all over the place here. If I have an issue, pulling back getInfo, then I am now routing my workflow item to my error queue with my message failed to retrieving doc info. The reason that I know how to pass these specific variables or these specific items into the function, again is just going back to the STL function.
If I go to workflow in my STL Index, go to route item, down here is my code example. I can just copy this exact code body and drop it into my script because all it is saying is it’s showing me I need my workflow item, I need my queue name and whatever note I’m applying to the routing action. Whatever string is put here is actually what’s reflected in the workflow history of the document. If you see a document moved from queue to queue and you break out the description, it will actually show that that string in there to give you a better idea of why something routed.
If I scroll down, and I want more information, the Method Route Item specifically talks about all of those variables that read in including the optional items. Again, I talked about STL all the time and the STL Index all the time because it truly does save a lot of time from the development perspective. Now that I’ve gotten all of my info for my document object, I am going to check the employee ID. The number one thing that this script hinges off of is the employee ID. If I don’t have an employee ID, then I can’t run my query because I won’t have anything to query against. I need to make sure that I have an employee ID first.
Now, I mentioned a minute ago that now because I have my INDocument object, I can grab whatever field value I want to pull back the value inside of that field. Let’s say my employee ID here is in field four of the document. I could put here, var amp ID = doc.field4. This would return my field four value. Now my employee ID would be whatever value is entered in field four right here, right? Well, I don’t always want to hard code that stuff directly into the script body because again I want this to be something that is able to move forward and change over time is needed. That’s why we defined up at the top of the script in Global Variables, that’s where we define which field contains the employee ID. Now I know that field four is where my employee ID is stored. When I come down here to this logic, instead of just typing doc.field4 and hard code in that right there, I can say doc and then say that the key is whatever the string is tied to employee ID.
This is essentially saying doc field four. This will pull back my field four value of the document. The next step is just my error handling. If my employee ID returns a blank value, then I know that there’s no employee ID and I need to route it to my error queue. Assuming that there is an employee ID, then I can move forward with the process. db = new DBAccess. This is where we’re actually starting the database access connection. DBAccess again is just an STL function where it’s told me I need to say the type, so my connection is through ODBC. I’m passing in my DBDSN name which again was defined inside of the configuration section, so this DBDSN is going to be Perceptive Content DSN. The DB user is the DB username or the database username that was defined at the top and the database password that was defined at the top.
Speaker 3:
Quick question.
Speaker 1:
Sure.
Speaker 3:
You’re using the same ODBC connection as the initial server, is that recommended?
Speaker 1:
No. Generally, what we’re going to do is if we are connecting to a database, it’s not going to be the INow database. Let’s just not say that you cannot use the INow database to store other tables. You can, but if you don’t need to, then I always say stay away from it. This is just for a test example. The functionality is there as an option if you have no other choice, but if you do have another choice, then I would say use a different table connected somewhere else or a different view and a different-
Speaker 3:
Most of the time, you’re going to be hitting a table on your HR system, your student system, which is a whole separate database anyway.
Speaker 1:
Correct.
Speaker 3:
Cool, thank you.
Speaker 1:
When I run this new DBAccess function, that’s going to instantiate my DBAccess. It’s not actually open yet. The next part is where I run the method to open the connection. It’s either going to return true or false, whether or not that connection is open. If it returns false, then I know that I did not connect to the database and I can run through my error handling. That’s what I have here. I’m able to open database, route to the error queue error connecting to database. Assuming that we connected successfully to the database, I can now update my query and run the query. Online 133 here, I have my employee query that I’m pulling in from the top section of my Global Variables.
My intention here is again to replace the employee ID string with my actual employee ID pulled from field four. I can do that pretty easily just with a replace action. This doesn’t require STL or anything. It’s just our standard replace function. I’m replacing the string that equals this exactly with my employee ID that I pulled previously from field four. Once this is done, my query no longer has this employee ID string in it. It’ll just have the actual employee ID and I can successfully run the query. Now, what I’ll do is create a cursor variable. On that cursor variable is just going to be whatever the database returns for my query.
From DBAccess, another function or a method that’s built into that DBAccess is our query. All it requires me to do is pass in the query string. Using DB, I query with my query string and whatever the query returns are applied to the cursor. That query return is going to be an object. The object keys will be whatever columns are returned in the query return and then the keys will then have the values stored in that column saved in the object. If I’m using our database, as an example here, go back over here. If I’m talking about first name, my first name column, when this query returns, I can do CSR first name. CSR first name. This will just equal whatever value is returned in that column from that query return.
After I run the query, I’m going to log the query out and I’ll show you what that looks like when we actually run the query. But this is another thing that you just tied into that DBAccess, it’s very handy. The query will show all of the different columns and all the values inside of the column. So, it’s easier easy for you as a human looking at the log to see what that query return contained. The next step is I don’t want to continue processing this if I don’t get a query return. I’m just doing a simple check of if the last name column is undefined, meaning that when I ran the query, it did not return that column, then I’m assuming that there is no query return and I can error to the error queue.
Assuming that it is not undefined, and it is populated and did return with values, now I’m going to move into my full name data massage. Basically, what I’m doing is setting full name to a blank value and then I’m checking to see if there’s a middle name because not everybody is going to have a middle name in the system. If the middle name column, if the middle name returned is blank, then what I’m going to do is build my full name variable off of csr.LAST_NAME which is the column for last name and should be the value that is stored in last name and then I’m using comma space to add as a string to it. csr.FIRST_NAME, which is the first name column, another space and I’m doing a substring of the middle name, so just to grab the first character and a period just to make it look nice. It should be last name, comma, space, first name, middle initial period.
If there is no middle name, then all I’m doing is last name, comma, space, first name. After that is complete. Now what I need to do is convert my birthdate. Let me explain why I need to do this. If we’re looking at a document inside of Perceptive Content, we have our index keys, field one through five, drawer, document type and our custom properties. These data types are going to be different depending on what they are. Index keys field one through five are always strings. If I have a date like a date of birth and I run the query, and inside of the database it’s stored as a datatype, I try to push that data type into a string like field two, it’s going to give me an error because it won’t accept that data type in that field.
What I have to do to get it into my field two field is to convert that date to a string first and then I can apply it to the index key. That is not the same for custom properties. That’s part of the reason why I have date of birth and index keys in my start date and custom properties, because I wanted to show you the difference between the two dates. My start date as a custom property actually is a date type. This I don’t need to convert. I can just take whatever the database has sent to me and pass it directly into that custom property and it will set it successfully. The only one I’m actually going to be converting is just the date of birth. The start date, I’ll just send straight through.
Here I’m using just another STL function, Convert to Date String, where I’m passing in my date of birth date data type that was returned from my query and I’m telling it what string format I want it to set in. This is super handy again in the STL. I can have different kind of date formats and pass that in and it will just know how to work with it. If I wanted to do, I don’t know, a two-character year that I could just do this, and it would know how to process that. I’m doing month, day, year for my string date return. Now that I have converted my date to a string, I’ve massaged my full name that I want to use inside of the index structure, now I can actually start indexing my document.
The first thing that I’m going to do is use the Reindex Document function to reindex the index keys. Again, remember that Reindex Document does not cover custom properties, so I’m going to be running Reindex Document to update the index keys, field one through five and then I’ll run Property Manager after this to then update the custom properties. Again, reindex, all everything that’s that here is explained in the STL Index, why I’m setting why I’m doing these keys and passing that into the Reindex Document. script. This is also just an example db. code that’s in that STL Index. What I’m doing here is I’m setting my new keys, my new INKeys item here.
Not everything needs to change. I do not intend on changing the drawer, the document type name or field four on this document. I want the drawer to stay HR. I want the document type to stay what the document type is. I want field four to stay my employee ID. The only things I want to update our field one through three and field five. I can’t just leave them out of the INKeys because INKeys is always expecting all of those items to be there. Instead, all I’m doing is just passing in whatever it already is. In this first section where I have drawer, I’ve just said doc.drawer to be passed in as drawer because doc is the INDocument objects that we read in earlier in the script and a drawer is a key of that object that contains my drawer name.
If I pass in doc.drawer, it’s just saying, “Make the drawer whatever it already is.” Full name is my massage name variable that I did up here. Birth date is my converted date that I did here. CSR position number, I didn’t need to do any massaging on this value. I pass the number straight in, so I’m just passing in whatever values in that column. doc.field4 is just like drawer. I don’t want field four to change, so I’m just passing in whatever it already is. Generate Unique ID is an STL function that generates those fields five unique IDs. I’m just dropping that function straight here. This will generate one of those field five unique IDs.
Then finally, docTypeName, that’s just going to be whatever doc type name is already on the document. Now that I actually have this keys variable, I can run my Reindex Document function. In my Reindex Document function, I’m passing in my INDocument object, so it knows what document it’s reindexing. I’m passing in the keys that I want it to update the document to and I’m giving it the reindex type. For this item, I’m just doing append. This is basically just saying renaming the current document, you could use Reindex Document to split documents apart. Maybe you keep your original document and then I create a new document with new keys off of that original document and then you could start moving pages around if you wanted to. For this scenario, all we’re doing is just reindexing the one document, so we don’t have to get too complicated with it.
After I run the Reindex Document function, that’s going to return a false if it fails. I again have my error handling here if new document is false, then I know that I failed to reindex my document and I’m going to route it to the error queue. Otherwise, I successfully reindex my document and my doc = newDoc. The only reason I’m saying doc = newDoc is because the code that was copied and pasted from the STL Index sets the Reindex Document to a new variable of new doc. I don’t want to continue using new doc as my INDocument object later on in the script. I want to keep using it just as doc because it’s easier and I already have doc everywhere else on the script, so I’m just setting it back to doc at the end of this so that I can continue using doc as the variable.
Now that we have reindex the document, we still have to update the custom properties. I’m starting up my Property Manager here and I’m passing in my properties of start date and supervisor. The way that Property Manager works is that it expects an array of objects to update custom properties. To make this a little bit easier to consume, let’s just talk about what I highlighted right here. Right now, it’s an array of two custom properties, but this what I have highlighted is really just one custom property and the value that we want to set it to. I’m saying the name of the custom property that I want to update is start date. and the value that I want to update it to is my cursor start date return. So, this is going to be just whatever the start date is in the database. And I’m setting that to the start date custom property.
Now with Property Manager, you do not have to update custom properties one by one by one. That’s why we have this as an array. With one Property Manager set action, I can update both start date and supervisor custom properties without having to loop through all bunch of different pm.sets. The properties variable that I have here is just my start date and my supervisor. The next step is where I’m actually setting the properties on that document. Just like DBAccess, Property Manager has its own methods that we can utilize within Property Manager and one of those is set.
Another one that is very handy that I’m not actually using in this script, but it’s good to point out is .get. If I wanted to pull information from custom properties, I could do a pm.get and say what the custom property name is of this property that I want or the value that I want to return, but with set, I’m setting the value. The only thing that I have to pass in is my INDocument object and my properties array that I built earlier. Assuming that that works, it’ll move on. Otherwise, it’ll return a false. I know that I have an error and I do more error handling. Really, at this point, our script is finished. I don’t have to do anything else. All I have to do is route it to the complete queue and we’re done.
I’m closing my cursor here as one of the last steps and I’m routing my document to the complete queue. Another thing that I’ve added here that I want to point out and be sure that I point out, is in the cache, I’m sorry, the final section of the script, I’ve added in this, this if (db) db.close. The very last thing that this script does is check to see if that DB connection is still open. If it is still open, then it closes it. If you are using DBAccess, this should always be in your finally statement because it’s just a guaranteed way to know that your database connection is always closing no matter what after the script runs which may not always be a problem if it’s left open depending on how often you’re running the script.
A lot of the time, especially for workflow scripts, if you’re running it every single time a document enters the queue, then you’re going to want to be sure that you’re closing that connection, so you don’t have just hundreds or thousands of open connections sitting around. That’s pretty much it for what’s inside of the script. Now, let’s just process it and I’ll show you how it works. All I’m going to be doing is taking documents from doc import, dropping them into doc indexing, letting the script run on it and then it will either move to complete or to error. The documents that I have inside of the workflow queue all have employee IDs that exist inside of the database. However, I do have one employee ID that is not in the database, so I can show you how error handling works.
First, I’ll just move one of these documents. I’m in my Document Import Queue. I’ll just move this one forward. I’m waiting for that indexing script to run. You can see my status is sitting, waiting for inbound action because my script is tied to the inbound action for that workbook queue. The workflow service in Perceptive Content kicks off incrementally. Even though the script may only take a second or something to run, sometimes a document can sit in a workflow queue for up to 30 seconds or so waiting for workflow agent to spin up and see that there’s a new document in the queue to kick the script off.
Our document has left the indexing queue. It’s either an indexing error, indexing complete, it was a valid employee ID. It should be an indexing complete and it is. I can open the document up. You can already see some of it has been indexed here. We have our full name, Taylor, Mary D., our date of birth which is the string, not the date data type. This is the converted string. Our position number, the employee ID did not change. Our unique ID that was created by the unique ID function, STL function. Our start date has been updated and our supervisor username has been input.
Let’s take a look at the log really quick and see what some of that looks like. This is the log for our scripts. It’s pretty small. You can make logs to look very pretty if you take a look in the STL Index in the Debug Section there are ways to indent logs, to organize them in ways that make it easier for a human to read. I didn’t do that just because this is a quick example, but definitely look at that. I try to make the logs as pretty as possible whenever I put a script together, not only for my benefit, but for the benefit of others that might use the script after me. Here we you can follow it through and see that our DBAccesses open, connected to the DB through DSN Perceptive Content. I’m running my query right here. The query is logged out so you can see that it updated with my employee ID and is no longer that bracketed employee ID.
Below here is the query return log, which I was mentioning earlier. It’s very handy. It shows you all of the column titles, all of the column names and then the values that are returned inside of those columns. If you ran a query … Let’s say that you weren’t doing this employee lookup, you’re doing a different query that would return multiple rows, those multiple rows would also log out here. You can see all of the data that’s returned. Very handy. After it logs out our query, you can see that we’re hitting our Reindex Document STL functions where it’s reindexing the INDocument object with our new updated information. You can see the name there.
After the document is reindexed, I have my log that mentions the successful reindex. Then we get into our Property Manager for custom properties. It shows right here that it is setting a start date, setting supervisor with our values that we’ve passed in. Again, here’s an example of, of the date data type. It logs out that I have my date there that it’s setting into that custom property. Then finally, my route item action that routes my document to indexing complete for reason, index and complete. That’s pretty much all that it is for how it’s running. Let’s run one of the bad ones. My 111111 employee ID that I do not have in the database, I’ll move that over to doc indexing.
Give the workflow service time to pick it up. That’s out of there. It should be in my error queue it is. I haven’t reindexed any of the document or anything. Let’s go into the log and we’ll take a look at what happened. I ran my query with my 111 employee ID. The query return shows no data. No data was returned from the query. I route my document to doc indexing error because no query return. This is what I was talking about when if you go into the workflow history, you can actually see that. I’ll open up the properties of this document. Breakout workflow. Click on the workflow that I’m in. Click on the History tab and I see a history of all of the different workflow queues that this document has been in.
If I expand my reasoning, no query return is now in my route reason. This is just what I passed in when I routed the document inside of iScript, so I can see specifically why it routed into the error queue. One thing to mention about this though is that the string links that it allows to show in this column is limited. Try to use as few characters as possible to get your point across inside of the reason. Even if it’s if it’s complicated, just saying look at the log where you can log out more detailed information, just keep that in mind that that you’re limited on your space and the reason column. That is my error document.
Lastly, let’s just take all of these documents and put them into doc indexing and I’ll just let them all process. They should all update with the appropriate data and move over to … It looks like one of them already processed. They’re already gone. See, that one was quick. Workflow agent must have flipped over right as I routed those forwards, so they all completed, went to complete. You can see that all my names updated. All my index keys are in place and everything looks like it’s working. That’s pretty much the presentation. I just wanted to show you guys how to do queries and how that wraps into documents inside of Perceptive Content.
There’s a lot more that we could talk about with iScript, but as you can see, it takes a long time to talk about each step of iScript. I always try to make these presentations like no more than 30 minutes. It always takes way longer than I expect. In the future, what we’d like to cover is how to do web service calls, either to update a document or to pass something along. There’s a lot of different stuff we want to show you with iScript so keep an eye out for more eye script related presentations, but I will move it over to questions from you guys. If you guys have any questions for me about anything that I showed you or just anything else related iScript or Perceptive Content in general.
Speaker 4:
If we don’t get any questions on this content, if there’s anything you’d like to see that we haven’t shown yet, we have 10 minutes so we can at least walk through how we might approach a problem.
Speaker 1:
I do also have a little bit, not too advanced, but a little bit more advanced way of setting custom properties that makes it easier for you to adjust it moving forward. If we don’t get a question, we’d go over that.
Speaker 4:
If you’re interested in seeing a RESTful web service call made out of iScript, I don’t know if we’re going to do a whole separate webinar on it, but I did do one as part of my digital signature Office Hours that we did about a month ago and that is available on our website as well. If you’d like to see an example of that, we do have it available.
Speaker 1:
Another thing we’d like to do two is start digging into eForms. I think eForms themselves are going to be their own kind of multi-Office Hours bit, but it’d be nice to also go through those. I don’t see any questions coming in. I’ll just use the rest of the time to show you what I added to just make custom properties a little bit more configurable. You can take this and really apply it to not just custom properties, I just only did custom properties because of our limited time, but here, what I have commented out is an object. It’s just a CP mapping object that I’ve put together.
So basically, what I’m saying is that I have a custom property of start date that I want to link to column start date, and a custom properties supervisor that I want to link to column supervisor. Now the nice thing about setting it up like this, instead of just hard coding it later on in the script is that let’s say that your query is much longer, maybe you potentially could index six or seven different custom properties or more off of this query. Right now, in the beginning, your view only covers maybe one or two of those custom properties, but you know that in the future, you’re going to want more.
Well, if I set it up in a configurable way like this where I’m specifying the custom property and what column that matches up to, using a loop later on in the logic later on in the body of the script, you can just loop through all these different objects inside of the array and you can dynamically adjust how many custom properties you’re setting based on each run. For example, if I have this CP mapping object and I come down to this other logic that I have commented out. To go back to where we’re setting the Property Manager, remember, I set properties of the array. It also itself is an array of just objects, where I’m saying start date and value is start date.
Well, I’m going to comment this out. We’re not going to use this anymore. Properties have gone. I’m still going to set properties in my pm set, but I’m going to build properties a little bit differently. This is the section that I had commented out before. Now instead of just hard coding properties with this data here, I’m setting properties as an array. And then I’m looping through my CP mapping object. Again, this is just what I have up at
the top of in the configuration section of my script, I’m setting that, I’m looping through each array of this. So, this should be two loops, zero and one here. Each line here is a different array position. So, when I looked through this, now I’m just pushing into my properties array and the name, which is my CP mapping array, position, I, dot, PCP. This should return the custom property name for whatever array position I’m on in my CP mapping object. The value is then equal to CSR, which is my cursor object and then I’m just passing in what the column name is here based on whichever array position we’re in on CP mapping. Really, what I’m doing here is I’m going to loop through however many custom properties we’ve added to the object in the configuration section and I’m just going to keep adding it until I’m done.
Then once I’m done pushing into properties, I can run pm.set and it should cover every single custom property that I have configured in configuration. If I take one of my documents complete, I’m just going to remove the custom properties here and save it. Let’s move this back to doc indexing and run it. Then assuming that I didn’t forget to comment something else out, it should work. It’s done. See, if you want to complete here, it did, open this up and I have my custom property set. The reason that I wanted to show you this is because you can make this even more advanced and include your index keys, right? Instead of having a CP mapping object, I could just do an index mapping object where instead of having CP names, I could just say like destination and my destination would be equal to either a custom property name or I could pass in field one as the string.
Later on, in the script, when I’m looping through all of these different object positions, I say if the destination, it has an index of field. If destination contains field anywhere in the strings, then I know that it’s an index key. I know to use Reindex Document. If it does not have field in the names, then I know it’s a custom property and I can use Property Manager to set the value. If it says drawer, then I know it’s a drawer and I can use Reindex Document to set the drawer. You can really make this as dynamic as you want it and you can just expand or retract the functionality moving forward very easily. These don’t have to be hard coded scripts. It just makes life a lot easier when you can make a little bit more configurable like that. I just wanted to show you some options.
That’s pretty much all I have to show. If nobody else has anything, then thank you very much for attending. We will definitely be having more of these. John is giving an Office Hours next month. I don’t know if you want to mention what that is.
John:
If you’re interested, I’m doing Office Hours on Microsoft Power Automate. It is Microsoft’s workflow and robotic process automation tool that’s available as part of Office 365. It integrates really easily with other Office applications like native, so automating things out of your email or into your email and within Microsoft Teams if you’re using that. Really, lots of other applications. They have a huge library of prebuilt integrations you can use for other web service or software services. I’m going to be giving a webinar on that. It’s cool because most Office 365 subscribers already have this, so there’s no real cost to trying it out. The registration link is available on our website. I think it’ll be a really great information session.
Speaker 1:
All right, well, thank you guys very much. I hope everybody has a great weekend and we will see you next time.
Want More Content?
Sign up and get access to all our new Knowledge Base content, including new and upcoming Webinars, Virtual User Groups, Product Demos, White Papers, & Case Studies.
Entire Knowledge Base
All Products, Solutions, & Professional Services






Contact Us to Get Started
Don’t Just Take Our Word for it!
See What Our Clients Have to Say
Denver Health
“RPI brought in senior people that our folks related to and were able to work with easily. Their folks have been approachable, they listen to us, and they have been responsive to our questions – and when we see things we want to do a little differently, they have listened and figured out how to make it happen. “
Keith Thompson
Director of ERP Applications
Atlanta Public Schools
“Prior to RPI, we were really struggling with our HR technology. They brought in expertise to provide solutions to business problems, thought leadership for our long term strategic planning, and they help us make sure we are implementing new initiatives in an order that doesn’t create problems in the future. RPI has been a God-send. “
Skye Duckett
Chief Human Resources Officer
Nuvance Health
“We knew our Accounts Payable processes were unsustainable for our planned growth and RPI Consultants offered a blueprint for automating our most time-intensive workflow – invoice processing.”
Miles McIvor
Accounting Systems Manager
San Diego State University
“Our favorite outcome of the solution is the automation, which enables us to provide better service to our customers. Also, our consultant, Michael Madsen, was knowledgeable, easy to work with, patient, dependable and flexible with his schedule.”
Catherine Love
Associate Human Resources Director
Bon Secours Health System
“RPI has more than just knowledge, their consultants are personable leaders who will drive more efficient solutions. They challenged us to think outside the box and to believe that we could design a best-practice solution with minimal ongoing costs.”
Joel Stafford
Director of Accounts Payable
Lippert Components
“We understood we required a robust, customized solution. RPI not only had the product expertise, they listened to our needs to make sure the project was a success.”
Chris Tozier
Director of Information Technology
Bassett Medical Center
“Overall the project went really well, I’m very pleased with the outcome. I don’t think having any other consulting team on the project would have been able to provide us as much knowledge as RPI has been able to. “
Sue Pokorny
Manager of HRIS & Compensation
MD National Capital Park & Planning Commission
“Working with Anne Bwogi [RPI Project Manager] is fun. She keeps us grounded and makes sure we are thoroughly engaged. We have a name for her – the Annetrack. The Annetrack is on schedule so you better get on board.”
Derek Morgan
ERP Business Analyst
Aspirus
“Our relationship with RPI is great, they are like an extension of the Aspirus team. When we have a question, we reach out to them and get answers right away. If we have a big project, we bounce it off them immediately to get their ideas and ask for their expertise.”
Jen Underwood
Director of Supply Chain Informatics and Systems
Our People are the Difference
And Our Culture is Our Greatest Asset
A lot of people say it, we really mean it. We recruit good people. People who are great at what they do and fun to work with. We look for diverse strengths and abilities, a passion for excellent client service, and an entrepreneurial drive to get the job done.
We also practice what we preach and use the industry’s leading software to help manage our projects, engage with our client project teams, and enable our team to stay connected and collaborate. This open, team-based approach gives each customer and project the cumulative value of our entire team’s knowledge and experience.
The RPI Consultants Blog
News, Announcements, Celebrations, & Upcoming Events
News & Announcements
Choosing the Right AP Invoice Automation Solution for 2025
Chris Arey2024-11-13T14:33:50+00:00November 12th, 2024|Blog|
Why Your ERP System Needs a Post-Implementation Audit
Chris Arey2024-11-01T14:02:10+00:00October 29th, 2024|Blog|
3 Key Insights from the 2024 Infor Velocity Summit
Chris Arey2024-10-21T18:48:08+00:00October 15th, 2024|Blog|
Healthcare Supply Chain Insights from AHRMM 2024
Chris Arey2024-10-06T16:42:23+00:00October 1st, 2024|Blog|
ERP Security: Issues to Consider & Best Practices to Follow
Chris Arey2024-09-21T10:00:15+00:00September 17th, 2024|Blog|
High Fives & Go Lives
AP Health Check at Jeffries Creates Path for Increased Efficiency, Visibility
Michael Hopkins2024-11-15T16:48:19+00:00November 30th, 2020|Blog, Brainware, High Fives & Go-Lives, Perceptive Content / ImageNow|
Customer Voices: Derek Morgan, MNCPPC
RPI Consultants2020-12-16T17:50:32+00:00August 14th, 2020|Blog, High Fives & Go-Lives, Infor CloudSuite & Lawson|
Voice of the Community: Jen Underwood, Aspirus
RPI Consultants2024-02-26T06:04:23+00:00March 14th, 2020|Blog, High Fives & Go-Lives, Infor CloudSuite & Lawson|
Voice of the Community: Keith, Denver Health
RPI Consultants2024-11-18T18:38:18+00:00March 14th, 2020|Blog, High Fives & Go-Lives, Infor CloudSuite & Lawson|
AP Automation Case Study at Nuvance Health
Michael Hopkins2024-11-15T15:52:56+00:00March 4th, 2020|Blog, High Fives & Go-Lives, Infor CloudSuite & Lawson, Knowledge Base, Kofax Intelligent Automation, Other Products & Solutions, Perceptive Content / ImageNow|
Upcoming Events
RPI Client Reception at CommunityLIVE 2019
RPI Consultants2024-02-26T06:09:32+00:00June 20th, 2019|Blog, Virtual Events, User Groups, & Conferences|
Free Two-Day Kofax RPA Workshop (Limited Availability)
RPI Consultants2024-02-26T13:24:38+00:00June 13th, 2019|Blog, Virtual Events, User Groups, & Conferences|
POSTPONED: Power Your Logistics Processes with a Digital Workforce with Kofax
RPI Consultants2024-02-26T13:29:29+00:00May 29th, 2019|Blog, Virtual Events, User Groups, & Conferences|
You’re Invited: Customer Appreciation Happy Hour
RPI Consultants2024-02-26T06:27:45+00:00March 14th, 2019|Blog, Virtual Events, User Groups, & Conferences|
RPI Consultants Sponsors 2019 Michigan Manufacturing Operations Conference
RPI Consultants2024-02-26T13:53:21+00:00January 30th, 2019|Blog, Virtual Events, User Groups, & Conferences|