John Marney:
Hello everyone. And welcome to another RPI Consultants webinar Wednesdays. Today we’re going to be discussing some frequently requested Brainware enhancements. There are things at that our clients often ask us for and that we implement. We wanted to share them, so you could get some ideas as to why it might be useful for your environment.
A few items real quick, of course, the side deck will be available to all attendees as well as a recording of this presentation will be available on YouTube. Of course as always, please submit any questions you have through our GoToWebinar questions pane inside of the GoToWebinar client. And of course as always, if you have any ideas for presentations that you would like to see, any topics, software solutions that you would like some more information on, we are happy to put that together, so please, just let us know.
Our agenda for today, we’ll give you a quick introduction and then we will jump into some enhancements that apply to pretty much anyone who has Brainware installed. They are not generally solutions specific. Then we’ll talk a little bit about Visibility reporting and how you can use that. The second half of the webinar will be around enhancements that are for specific use cases, generally for just Distiller for invoices or invoice processing but not necessarily. Then we’ll wrap up with some questions.
I am John Marney, for those who don’t know me. I am the manager of Solution Delivery on the imaging team. I have extensive experience in designing and implementing various software products and solutions, from Kofax to Perceptive to OnBase. Most of my experience does lay in the accounts payable space for health care organizations and manufacturing organizations though I have done a huge variety of various projects. And I’m a proud K State alumni.
Michael Madsen:
Hello. My name is Michael Madsen. I’m a senior consultant. I generally work with designing and implementing Hyland products. A lot of the areas that I work in are going to be around manufacturing. Also, accounts payable and higher education. And luckily I am the office Dungeon Master so get those d20’s warm.
John Marney:
All right. So a little bit about RPI. We are 80 plus full time consultants, project managers, developers. We have offices in Baltimore, Tampa, and right here in Kansas City where our team is based. We run the gambit of professional services. So whether it’s a new implementation or a redesign, an upgrade or managed services, we can support you.
We are partners with a number of different organizations and work with a variety of products Infor who makes Lawson, is one of our big ones. We’re also partners with Kofax and of course, Hyland. Hyland are the owners of Brainware if not the creators, and as OnBase and we are partners with them, supporting again implementations, upgrades, and a variety of other services.
So we have a lot of experience with the Brainware platform and so today we’re-
Michael Madsen:
We’re going to talk about some general enhancements for capture. These are a lot of questions that people have come up to us about some of the solutions that we’ve designed around them. We’re assuming that lot of people who have joined already have a basic understanding of capture so we’re just going to jump right into the enhancements.
John Marney:
Oh, that’s too many slides.
Michael Madsen:
So our first one we’re going to go over is large documents. So a lot of businesses will pull in invoices or document types for other business processes that have multiple pages. Problem with these is that they can take a long time to process inside of capture. They consume a lot of your licensed page count and then in the end they end up having poor OCR results and the extraction generally fails anyway. So you’re generally having to verifiers touch all of them regardless.
John Marney:
And so to solve that, you can do one or all of these things. One of the first things you could set up is to create a separate RTS instance. Those are these server-side processes that chew through your documents and perform OCR and extraction. So you can actually set up one specifically for handling only large documents so that the smaller documents or normal size documents can continue to process through the normal server-side processes. This is important because if you accidentally even submit a 200 page document, which may not even be on purpose. It would have meant to be split into small documents. But if you do that, it’s going hang the server-side processes are going to hang up on that large document and not let anything else through. So creating a separate avenue for the large documents to process can help with throughput.
On top of that you could set that new RTS instance up to only OCR the first and last page or first two pages and the last page to save on that page count in your licenses. It also allows you to maybe only capture header data on that document to still help with the manual entry but allow the users to manual enter the detail information which can actually be beneficial for those larger documents.
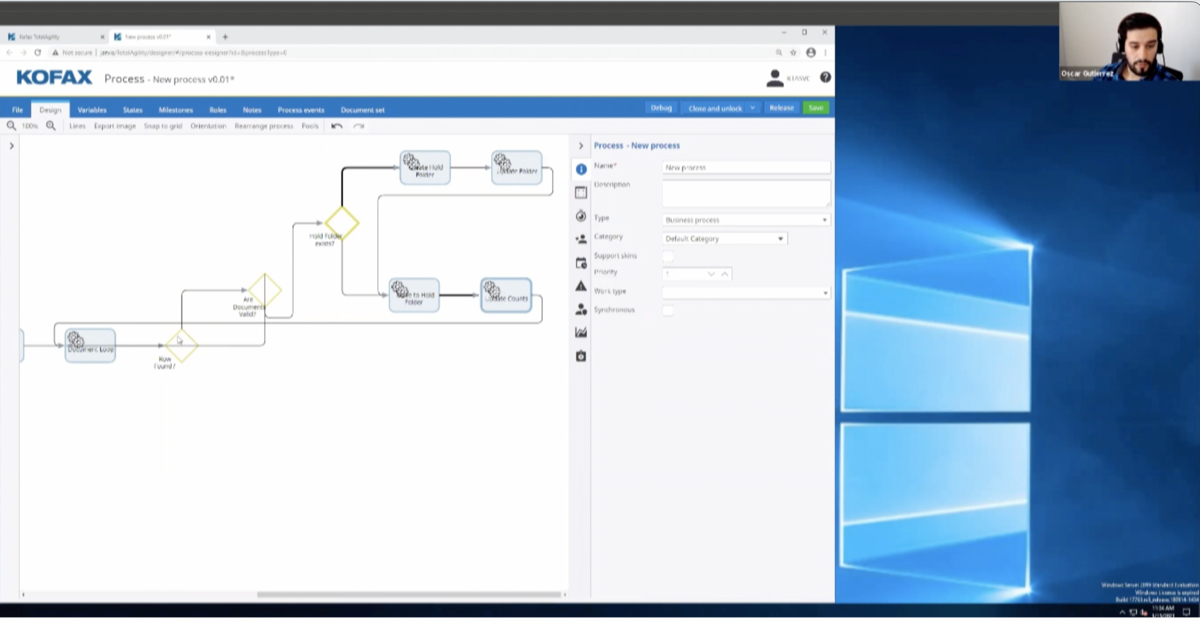
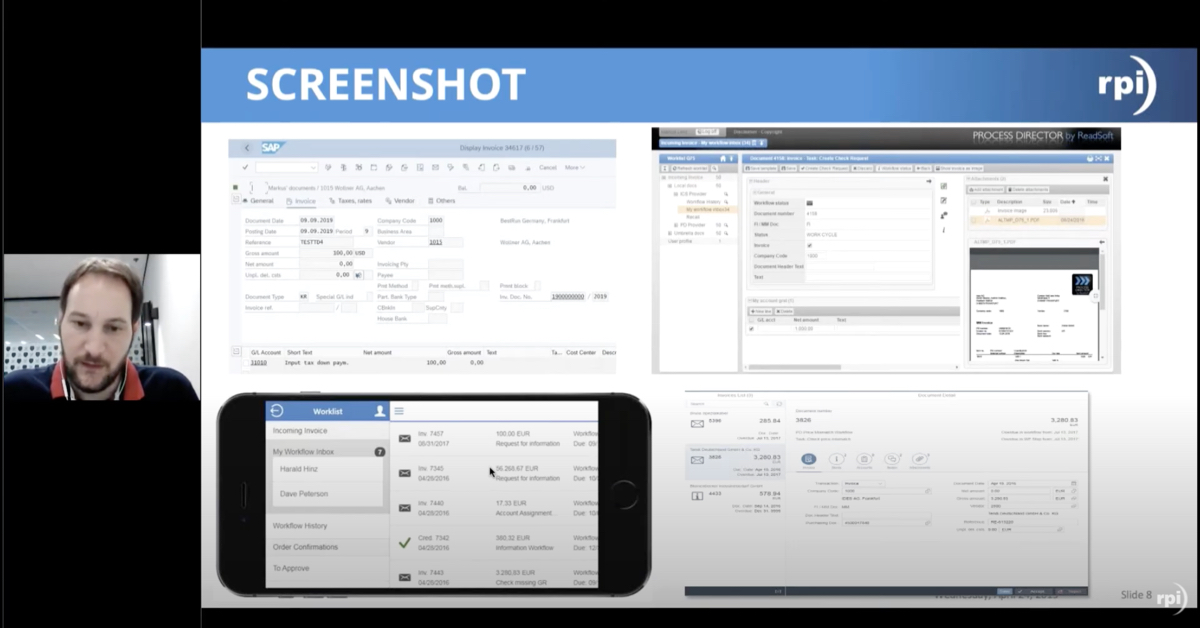
And we have a quick screen shot of that RTS instance. It’s a little small but if you look closely you can see that there’s an option to configure only OCRing certain first and last pages of a document.
Michael Madsen:
Yeah, and it’s important to remember that it’s not … you’re not specifically barred to the first two and last one, it can be whatever you set up inside of those properties.
John Marney:
Generally we would set this up to be anything larger than, say five or ten page documents. All right, what’s our next problem?
Michael Madsen:
So additional validation rules. The out of the box solution allows users to enter invalid information. So what we mean by this is like if you have a date field or something like that when you pass that information along into your workflow process, that date may be formatted in a way that can’t be read by something else. So now you have to … it has to go to an exception queue where somebody goes in and manually fixes that.
John Marney:
So the solution to this is a variety of different things and this may be a variety different problems. In the example of date formatting, we can force users to enter dates in a certain way or if they enter it incorrectly, the form won’t validate. You also have options around conditional formatting and conditional fields such as if one field or if your date occurs in the future, let’s say it’s an invoice date or a transcript date, we can cause it to throw an error and require a selection on other field, saying, “Confirming? Yes, this is in the future.”
And of course, custom fields can be added to drive further downstream logic so it there’s anything not being extracted or not being validated, that can always be added.
Michael Madsen:
Query performance is a common problem. A lot of the time if you have certain documents that are always running the same queries or LOOKUPs, if that LOOKUP takes a long time, your throughput will be greatly increased in regards to how many batches you’re processing a certain period of time. So there’s a lot of different things that we can do to enhance the query performance and your throughput.
John Marney:
Right. So this could be both a server-side problem and how long documents take to process. Can also be client-side problem and what the users actually experience in latency there. And the solution may not necessarily even be Brainware specific. We may not have to make changes to Brainware. We can actually help you analyze the performance of those queries on the target database and see how we can rewrite that query to improve performance. We could also … so we can take those queries and implement them either on the view on the database that you’re using. We can change it to the call to user store procedure instead, which doesn’t necessarily increase performance but it allow for options on how we’re filtering data and calling which can actually net in a performance increase.
Michael Madsen:
So duplicates are generally handled in your ECM post capture. But this is a problem because we’re wasting time in the verifier process, and the OCR extraction process. So if we can figure out how to identify those duplicates in the beginning, then we don’t have to worry about spending the extra time to work later on.
John Marney:
Right. And this is not … it’s commonly believed that this should be something that is configured out of the box, but it actually is a commonly requested thing that we need to build as an enhancement. So we can actually implement duplicate check in Brainware, and it can be checking against your ERP, your student information system, against your ECM, against your workflow, against any other system that where we can check and present an error to the users say, “This may be a duplicate,” to allow them to use an invalid reason, to not have to verify that data or even void the documents so that they can just remove it from their processing altogether.
Michael Madsen:
So the next item is split batches by user. Based on your business process, not every user needs to look at … or ever verifier needs to look at every batch and verifier. There may be specific vendors that they work with or something like that if you’re in a accounts payable department. And it wastes a lot of time having the users trying to identify the specific batches that they need to work on. Well, we can adjust that by pulling information in through the extraction process.
John Marney:
So the solution here is really allow users to work on only the documents they need to work on. If we’re feeding information into Brainware such as what users actually captured a document or batch, we can actually split the batches so that only those users can see them, therefore they would end up only having to verify the stuff that they need to. And that would allow users to more easily see and search through their own batches.
Michael Madsen:
So Brainware comes with a certain set of customer or invalid reason codes out of the box. There are going to be things that you can utilize to try to force a batch through so you can get it extracted and into the rest of your process. However, the ones that come out of the box aren’t always what you’re looking for or don’t always meet your needs. So just remember that we can create new ones.
John Marney:
Absolutely. So custom codes can be implemented on top of what you have right now and they can be for any business rule. They can also contain new logic so what I mean by that is each invalid reason codes specifics which fields no longer need to be required or validated. We can add logic on top of what exist already to require or not require a field.
Michael Madsen:
So a big issue that people have with Brainware is they don’t even know where to locate their problem areas. So you may have documents that read in, have a specific field that it fails on every single time for this specific vendor and how are you supposed to find that? Well you can find that information through Visibility reporting.
John Marney:
So yeah, Visibility reporting can provide a ton of different metrics. Most owners of Brainware actually already own Visibility. It’s generally a package sale, and you may not even know it. There are many of out of the box reports in the system that can help inform where inefficiencies exist. So whether you were talking about how many documents individual verifier users are verifying on a given day, week or year, whether you want field by field information to identify specific input methods, capture methods, specific vendors or whatnot that are inefficient. Those reports generally already exist so you don’t really need the custom reporting.
We actually have a previous webinar we did about a year ago on Visibility reporting specifically. So you can get that on our website and in that you can get some help identifying whether you already own it and if you don’t know, please feel free to contact us.
Quick screen shot of just a sample report. This one is showing extraction rates and document volume over the last 30 days. So see on the screen shot and in this instance this client had processed 90,000 documents in the last 30 days. And we’re getting … and 16% of them required a verifier interaction.
Okay. So jumping into some more solutions specific enhancements. There are really mostly around invoice processing where we see most of our Brainware users. However, they may yet apply to other use cases.
So the first problem somewhat related to what we’ve already talked about is that there are extra fields required based on your business system that aren’t out of the box and sometimes aren’t easily configured using the GUI tools. So this could be something like a PO type that goes along with your PO number that you maybe at least need users to see even if it’s not extracted. It also could be something like a vendor sub type so do you want it classified as a service vendor or utility vendor.
Michael Madsen:
Yep. So we can take Distiller and configure some of those custom fields and then we could also extract specific values based on custom queries or connections to the ERP. So like John said a good example is PO types so if I have a service handling code on a PO I know to send that service handling code with the document when we export it instead of requiring your ECM or other work load process to pick it up later.
John Marney:
Alongside of that, we also have frequent requests for per vendor enhancements. So a lot of times, this is driven by those Visibility reports we’ve mentioned were we can identify one vendor specifically has a certain field failing and that always requires manual intervention. So a good example of this is if you have an invoice number on the document, that has the letters INV and then the numbers zero, one, two, three, four, five, perhaps that invoice the way it’s printed that zero always reads as a capital O.
Michael Madsen:
And some things that we can help with this, is obviously if you have problem invoices for a vendor, you’ve got a collection of those, you can actually create learn sets, read those in, try to increase your OCR extraction rates but we can also implement custom codes. So if we have a vendor where to use John’s example, and they have an invoice number that starts with INV and will always have a number after that, we can input custom code that knows to never accept a letter and to only accept a number. So we’re to always set it if it sees an O, to set it as a zero.
John Marney:
And quick screen shot just of what invalid fields look like. Here we have an example of an invoice number using a one instead of I which is also a very common failure. So as Mike had mentioned, you know we can add custom code to only accept certain types of characters or certain characters specifically.
Another one that we’re seeing more and more often is that where a US based company may have implemented Brainware to process primarily for their US business units, they do want to expand to business units or clients that are overseas, in this case in EMEA region or largely Europe. Of course, Europe has their own tax requirements. So that would include things like a value-added tax ID that is extracted off of the invoice for each vendor. It can also be tax codes and special tax rates that apply at the detail level.
Michael Madsen:
And custom configuration we can either extract it from the document if it exists on the document, or utilize like a vendor ID or business unit to determine what those codes are and then we can take it even a step further and apply that to certain calculations if we need to do that inside of Brainware.
John Marney:
And you’ll see in this screen shot up on the top right we have a bad ID that was either extracted off of the document or pulled in from the ERP.
Related to the last one, not quite as complex as EMEA taxes, you also have Canadian taxes and will generally apply to US based companies that are wanting to work with Canadian vendors even. So you don’t have the complexity of that generally but you do have a couple of special tax calculations that need to happen.
Michael Madsen:
Yep. And this just kind of ties back into the last slide where we can implement some kind of custom configuration to search for those codes and apply that calculation to the output.
John Marney:
All right. So that is the high level. There are a ton of different things that you can do with Brainware. However, we weren’t able to touch on all of them. We are open to take any questions that there are right now. While see if there’s any questions we do have some other resources, so the archive knowledge base is on our website, rpic.com. We also have a number of older webinars like I’ve mentioned that Visibility webinar, if you’re interested in that, that is one our website as well.
Speaker 3:
Hey, guys we have one question here and it is how many learn sets can you have without system performance issues?
John Marney:
That’s a great question. So the rule of thumb if I recall correctly was you know when we started doing these implementations we would say no more than 20 or something like that. It really is going to vary a lot and its partly going to vary depending on your hardware. It’s going to vary depending on the complexity of those learn sets. We have clients who have a lot more than that. We also have clients who don’t use learn sets because of the potential performance impact. And what we do in that case is we will use custom code instead because that is more use case specific and doesn’t rely on the template matching which can impact the entire throughput negatively that learn sets have the potential for.
Michael Madsen:
Right and with that custom code we can kind of identify things that are on the invoice without looking at the template, just looking at certain items on the invoice to then, within the code know specifically what kind of invoices should be and apply those custom configurations there.
Speaker 3:
Next question. I think I know the answer. We have someone asking if you have any additional information on creating learn sets? I don’t believe we have … do we have a white paper on that yet?
John Marney:
I don’t think we have anything prepared. I believe there’s a decent amount of documentation available on the Hyland portal. The Brainware documentation is very thorough to the point of being probably too much for the average user to really dig through. But there is information on there about how to set up a learn set. We also do provide training on that if that’s something you want to on.
All right. Sounds like that’s it. Of course, if you have any more questions feel free to shoot them to us in an email and thank you for joining us today.
Michael Madsen:
Thank you.